
Claude Sonnet 5 是 Anthropic 新一代 Sonnet 模型,重点提升了推理、工具调用、编码和长链路任务执行能力。它在 agentic 场景中明显缩小了与 Opus 4.8 的差距,同时以更低价格覆盖更多日常开发和知识工作场景。
系列:AI 模型观察 2 / 2
- 1 baidu/Unlimited-OCR 模型介绍:长文档 OCR 的新选择
- 2 Claude Sonnet 5 发布:更像 Agent 的 Sonnet 模型 当前
Anthropic 发布了 Claude Sonnet 5。
这次升级的关键词不是“更会聊天”,而是 更像 Agent:它更擅长制定计划、调用工具、操作浏览器和终端,并在多步骤任务中持续推进,而不是做到一半就停下来。
如果说 Claude Sonnet 3.5、3.6、3.7 让很多开发者第一次感受到“模型可以写代码、用工具、协助开发”,那么 Sonnet 5 的意义在于:它把过去更偏 Opus 级别的 agentic 能力,往成本更低的 Sonnet 档位推进了一大步。
核心判断
Claude Sonnet 5 是一个面向 Agent Coding 和日常自动化任务的高性价比模型。
它不是 Anthropic 最强的模型,Opus 4.8 仍然更适合最复杂、最关键、最需要深度推理的任务。但 Sonnet 5 的价值在于:它在很多 agentic 工作流里已经接近 Opus 4.8,同时价格明显更低。
这意味着它很可能会成为很多团队的默认执行层模型。
Sonnet 5 主要提升了什么
原文把 Sonnet 5 描述为“目前最 agentic 的 Sonnet 模型”。
这类能力主要体现在几个方面:
- 推理能力更强:能在复杂任务里保持更稳定的计划和判断。
- 工具使用更强:更适合浏览器、终端、代码工具、业务系统等多工具链场景。
- 编码能力更强:更能处理多步骤软件工程任务,而不是只写片段代码。
- 知识工作更强:更适合研究、分析、搜索、整理、归纳等任务。
- 长链路跟进更强:能把任务从开始推进到验证,而不是中途停止。
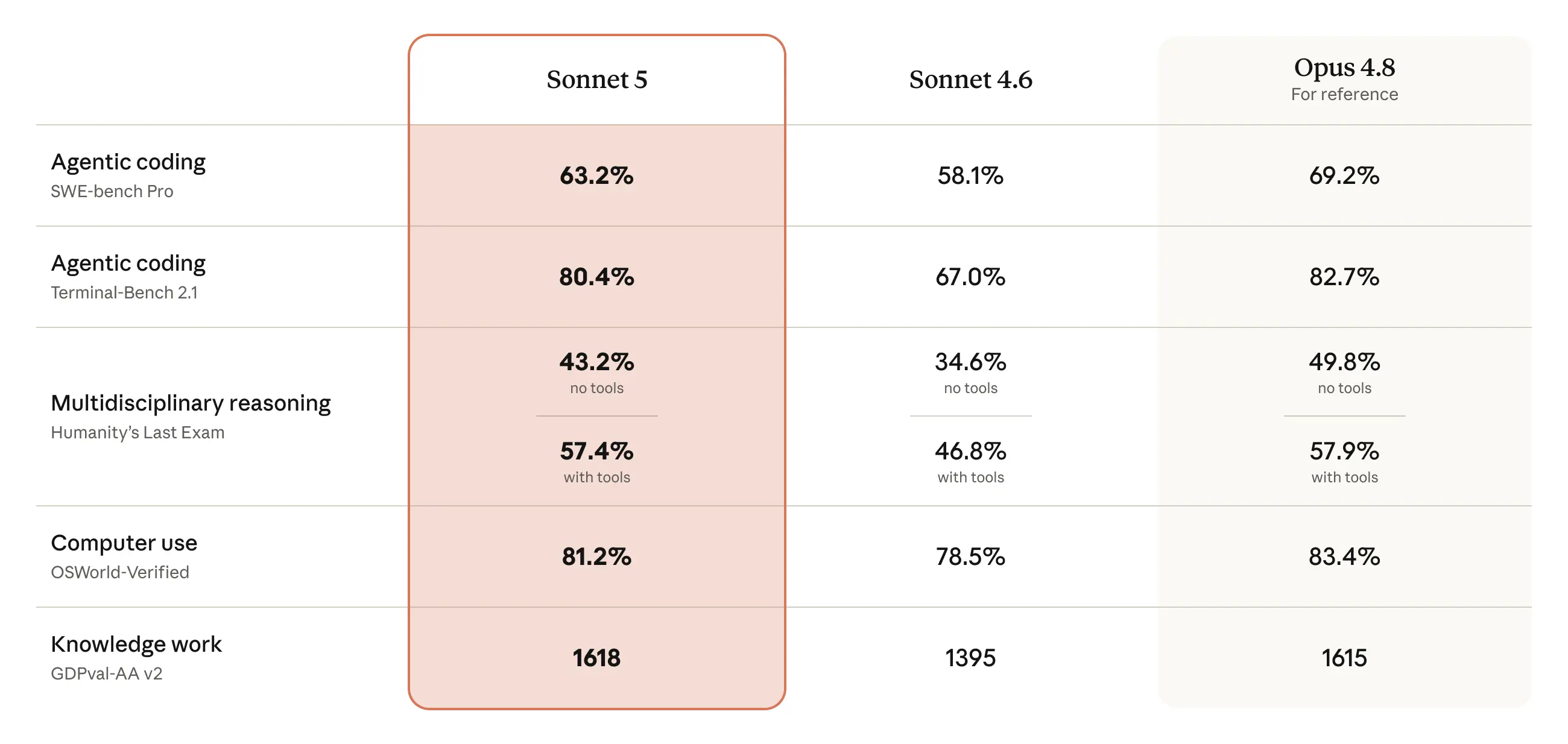
从 Anthropic 给出的对比来看,Sonnet 5 相比 Sonnet 4.6 在多个评测上都有明显提升,并且在一些 agentic 场景中接近 Opus 4.8。
更重要的是,它覆盖了更宽的成本-性能区间。用户可以通过 effort level 调整模型投入的推理强度,在成本和效果之间找到平衡。
为什么它对 Agent Coding 重要
Agent Coding 的核心不是“模型能不能写一段函数”,而是它能否独立完成一条完整工程链路:
- 理解目标。
- 阅读现有代码。
- 制定修改计划。
- 实现代码。
- 调用工具验证。
- 发现错误后修复。
- 输出可审查的结果。
过去很多 Sonnet 级模型的问题是:单步能力不错,但长链路容易停在中间。
例如:
- 写了代码,但不跑测试。
- 找到 bug,但没有写复现用例。
- 修了表面问题,但没有确认根因。
- 做了前半段自动化,后半段需要人接手。
- 上下文复杂时,容易忘掉原计划。
Sonnet 5 的提升重点正好对应这些问题。
早期测试反馈里,多个团队提到它更能完成端到端任务:持续编码、工具调用、调试、处理 messy technical context、针对真实 PR 做完整修复、在 brownfield code 中追踪根因。这些反馈说明它不只是 benchmark 变好,而是更贴近真实开发工作流。
它适合做什么
从定位和能力结构看,Sonnet 5 更适合以下几类场景:
1. 日常 Agent Coding
包括:
- 小到中型功能开发。
- bug 调查和修复。
- 写测试。
- 重构局部模块。
- 阅读项目代码并给出改动计划。
- 处理真实 PR。
如果任务需要模型自己读代码、跑命令、修复失败、再验证,Sonnet 5 会比上一代 Sonnet 更合适。
2. 多步骤自动化流程
例如:
- 更新 CRM 数据后发送通知。
- 读取后台系统并整理报告。
- 执行业务操作后生成记录。
- 在多个工具之间搬运、验证、汇总信息。
这类任务的关键不是单次回答质量,而是 follow-through:模型能不能把多步流程做完。
3. 知识工作和研究
包括:
- 搜索资料。
- 对比文档。
- 整理证据。
- 写分析报告。
- 归纳长文本。
- 根据资料输出决策建议。
Sonnet 5 在工具调用和知识工作上的提升,使它适合承担“研究助理”角色。
4. 中等复杂度的业务 Agent
比如:
- 法律文档初步研究。
- 数据分析助手。
- 保险流程自动化。
- 客户支持辅助。
- 内部运营自动化。
前提是必须有权限控制、审计、人工确认和安全边界。
它不适合什么
Sonnet 5 很强,但不代表所有任务都应该交给它。
1. 极高风险决策
涉及资金、法律责任、医疗决策、安全事故、生产变更等场景,Sonnet 5 可以辅助分析,但不应该自动拍板。
2. 最复杂推理任务
如果任务需要最高级别的推理、最长链路规划、最强代码能力,Opus 4.8 仍然可能更合适。
3. 高风险网络安全任务
原文明确提到,Sonnet 5 没有被刻意训练用于网络安全任务,虽然能做一些常规、无害的 cyber 任务,但在危险 cyber 技能评估上明显弱于 Opus 级模型。
Anthropic 也为 Sonnet 5 默认开启了实时 cyber safeguards。
这说明它不是面向高级攻防自动化的模型。
4. 没有工具和验证闭环的 Agent
Sonnet 5 的价值来自工具调用和长链路执行。如果你的系统不给它浏览器、终端、测试、数据库、业务 API 等工具,它的 agentic 能力发挥会被限制。
换句话说,只把它当普通聊天模型用,会浪费它的主要优势。
安全评估怎么看
原文给出的安全结论比较明确:
- Sonnet 5 整体上比 Sonnet 4.6 更安全。
- 在 agentic safety 上更擅长拒绝恶意请求。
- 对 prompt injection hijack 的抵抗更好。
- 幻觉和迎合倾向低于 Sonnet 4.6。
- 自动行为审计中,整体不良行为率低于 Sonnet 4.6。
但它也不是“安全问题已经解决”。
原文同时提到,在某些不良行为评估上,它相比更强的 Opus 4.8 和 Claude Mythos Preview 仍有更高比例。因此真实产品落地时,不能只依赖模型本身,还需要:
- 权限隔离。
- 工具调用审计。
- 高风险操作二次确认。
- prompt injection 防护。
- 输出验证。
- 敏感数据最小暴露。
对于 Agent 系统来说,模型安全只是第一层,系统治理才是关键。
价格和可用性
根据原文,Claude Sonnet 5 已面向所有计划可用:
- Free 和 Pro 默认使用 Sonnet 5。
- Max、Team、Enterprise 用户可用。
- Claude Code 可用。
- Claude Platform 可用。
- API 模型名为
claude-sonnet-5。
价格方面:
| 时间 | 输入价格 | 输出价格 |
|---|---|---|
| 2026-08-31 前 introductory pricing | $2 / 百万 input tokens | $10 / 百万 output tokens |
| 之后标准价格 | $3 / 百万 input tokens | $15 / 百万 output tokens |
还有一个细节要注意:Sonnet 5 使用了更新后的 tokenizer,同样输入可能映射为更多 token,原文给出的范围大约是 1.0-1.35 倍,取决于内容类型。
Anthropic 表示 introductory pricing 的设置,是为了让从 Sonnet 4.6 迁移到 Sonnet 5 的成本大致保持中性。
怎么选:Sonnet 5 还是 Opus 4.8
可以按任务复杂度和风险等级这样选择:
| 场景 | 推荐 |
|---|---|
| 日常编码、修 bug、写测试 | Sonnet 5 |
| 多步骤自动化、内部业务 Agent | Sonnet 5 |
| 成本敏感的大量 agentic 任务 | Sonnet 5 |
| 复杂架构设计、关键推理、困难问题攻坚 | Opus 4.8 |
| 高风险安全、法律、生产决策 | Opus 4.8 + 人类审核 |
| 需要先快速探索、再局部升级 | Sonnet 5 起步,必要时切 Opus 4.8 |
更稳妥的工程策略是:
- 默认用 Sonnet 5 承担执行层。
- 任务复杂、失败成本高、需要更强判断时升级到 Opus 4.8。
- 用 effort level 在成本和质量之间调节。
- 对所有工具调用加权限和审计。
对开发者的实际意义
Sonnet 5 的发布,说明 agentic AI 的能力正在从“旗舰模型专属”向“更便宜的默认模型”下沉。
这对开发者有三个影响。
第一,Agent Coding 的成本会下降。过去必须用更贵模型才能跑通的长链路任务,现在可以先用 Sonnet 5 承担。
第二,AI 自动化的适用范围会扩大。更多 CRM、内部系统、数据分析、知识工作流程,可以尝试用 Sonnet 5 做执行层。
第三,团队需要重新设计模型路由。不是所有任务都用最强模型,而是按任务难度、风险和成本动态选择。
我的结论
Claude Sonnet 5 是一个值得重点关注的模型。
它的核心价值不是单点能力提升,而是让更强的 agentic 能力进入更低成本档位。对于软件开发、工具调用、多步骤自动化和知识工作来说,它很可能成为新的默认选择。
它适合承担:
- Agent Coding 的执行层。
- 日常开发助手。
- 内部业务自动化 Agent。
- 研究和知识工作助手。
- 成本敏感的大规模工具调用任务。
但它不应该被理解成“全自动替代人类决策”的模型。越是 agentic,越需要系统层面的权限、验证、审计和人工确认。
一句话:
Sonnet 5 让“能做事的 AI”变得更便宜、更普及,但真正可靠的 Agent 仍然取决于模型、工具、流程和安全边界的组合。
参考: